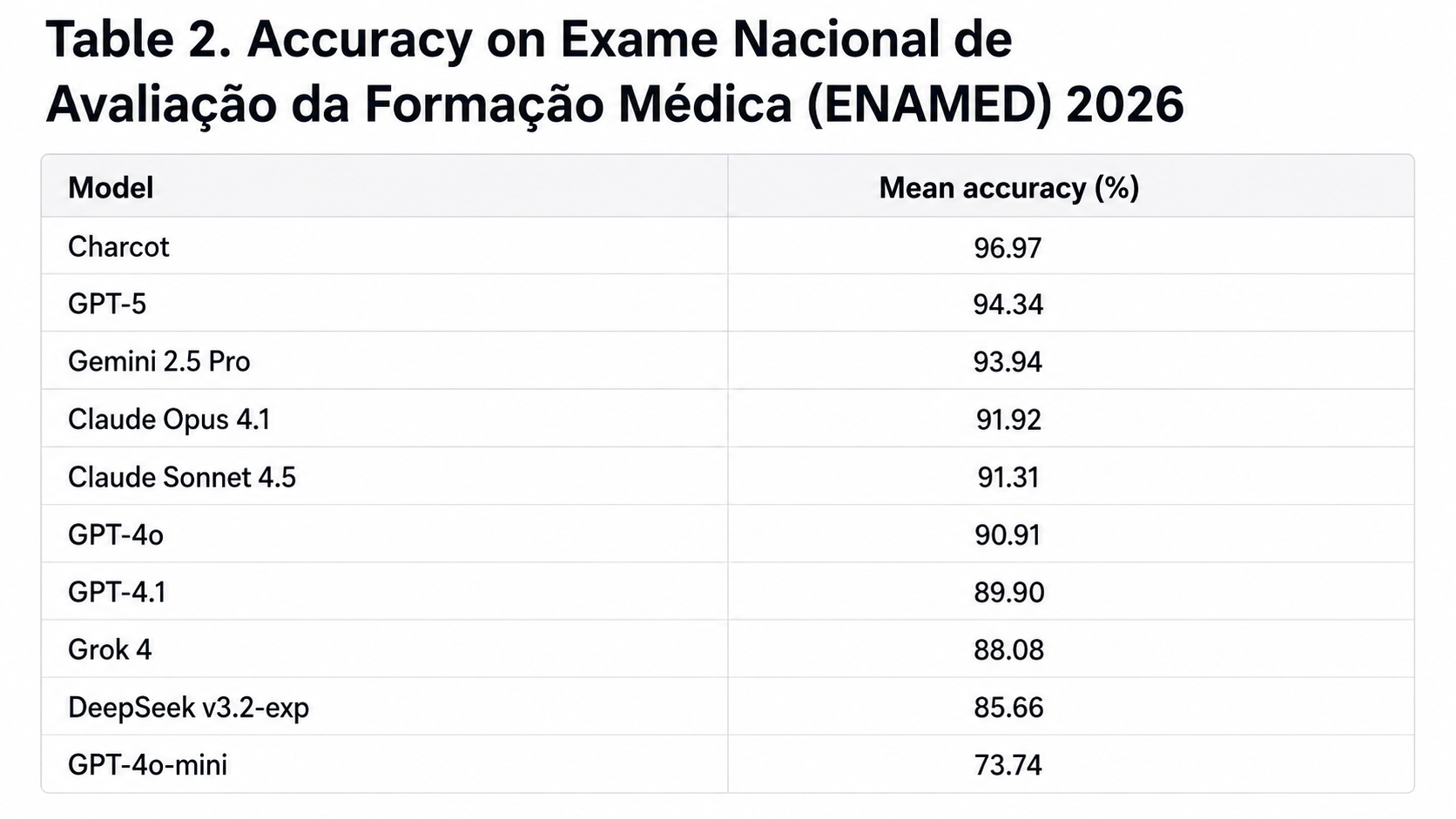
O Charcot, agente clínico da Voa Health que utiliza o contexto do paciente para apoiar o raciocínio médico, oferecer evidências e agilizar tarefas da prática clínica, apresentou o melhor desempenho em um estudo científico que comparou dez modelos de linguagem de larga escala (LLMs) na resolução do Exame Nacional de Avaliação da Formação Médica (ENAMED) de 2026. Especializada em medicina, desenvolvida para a língua portuguesa e treinada com diretrizes clínicas brasileiras, a IA da Voa alcançou 96,97% de acertos, o maior índice entre os modelos avaliados, à frente de GPT-5, Gemini 2.5 Pro, Claude Opus 4.1 e outras ferramentas globais de IA.
Conduzido por pesquisadores da Pontifícia Universidade Católica do Paraná (PUCPR), Universidade Federal do Paraná (UFPR), Instituto Tecnológico de Aeronáutica (ITA) e The Ohio State University, o estudo Performance of Large Language Models on the Brazilian National Medical Education Examination: Comparative Benchmark Study foi publicado em 29 de maio de 2026 no Journal of Medical Internet Research (JMIR), uma das principais revistas científicas da área de saúde digital.
O objetivo foi quantificar e comparar o desempenho de modelos comerciais de ponta em relação ao Charcot, uma IA brasileira especializada, avaliando a precisão, a consistência e a capacidade dessas ferramentas de responder a questões que abrangem diferentes áreas da medicina. Segundo os autores do estudo, compreender até que ponto esses sistemas conseguem lidar com desafios clínicos complexos é um passo importante para sua adoção segura e responsável na prática médica.
Como o benchmark de IA médica comparou Charcot, GPT-5 e outros modelos
O ENAMED 2026 trouxe 100 questões de múltipla escolha, abrangendo clínica médica, cirurgia, atenção primária, saúde pública, pediatria e ginecologia-obstetrícia. Depois da anulação de um item (questão 10), o benchmark considerou 99 questões válidas para as análises de desempenho. Cada modelo realizou a prova completa em cinco rodadas independentes, com randomização da ordem das questões e das alternativas em cada rodada, totalizando 495 respostas. Todas as IAs receberam os mesmos prompts em português, solicitando a indicação da alternativa e uma justificativa concisa para cada questão.
Embora nove dos 10 modelos avaliados tenham alcançado mais de 85% de acertos, os pesquisadores observaram diferenças de desempenho importantes quando as questões envolviam protocolos clínicos, diretrizes nacionais e aspectos específicos da prática médica brasileira. Nessas situações, o Charcot apresentou desempenho superior aos concorrentes, sugerindo que especialização em medicina, língua portuguesa e contexto local podem representar uma vantagem importante mesmo diante dos mais avançados modelos generalistas disponíveis atualmente.
Em relação ao grupo de elite, formado por GPT-5 e Gemini 2.5 Pro, o desempenho do Charcot foi considerado estatisticamente indistinguível. Ainda assim, o modelo da Voa Health mostrou maior alinhamento com recomendações e respostas esperadas no contexto brasileiro em questões sobre tuberculose e derrame pleural, por exemplo.
“A medicina é influenciada por diretrizes locais, pelo perfil da população e pelo funcionamento do sistema de saúde. Por isso, avaliar sistemas de IA no contexto brasileiro é essencial. Os resultados mostram que soluções desenvolvidas com foco podem apresentar respostas mais alinhadas às necessidades da prática médica no país, sempre com supervisão profissional e uso responsável”, explica o médico e pesquisador Gustavo Lenci Marques, Clinical Research Leader da Voa Health e um dos autores do estudo.
Principais resultados:
- Charcot: 96,97% de acertos.
- GPT-5: 94,34%.
- Gemini 2.5 Pro: 93,94%.
- Claude Opus 4.1: 91,92%.
- Nove dos dez modelos superaram 85% de acertos.
- Charcot teve melhor desempenho em questões ligadas a diretrizes brasileiras.
Por que esse benchmark de IA médica é importante para o Brasil
Estudos de benchmark como esse desempenham um papel fundamental no avanço da inteligência artificial aplicada à saúde. Ao submeter diferentes modelos às mesmas condições de teste, eles permitem comparar desempenho, identificar limitações e gerar evidências mais confiáveis sobre a capacidade dessas ferramentas de lidar com problemas clínicos complexos. A publicação dos resultados no JMIR Medical Education, uma das principais revistas científicas internacionais dedicadas à saúde digital, reforça a credibilidade do trabalho e amplia sua relevância para pesquisadores, médicos e desenvolvedores de IA.
Para a medicina brasileira, o significado é ainda maior. O estudo em questão é um dos primeiros benchmarks publicados em periódico científico internacional a utilizar um exame médico nacional de alta complexidade, aplicado em português e baseado em diretrizes, protocolos e características epidemiológicas do país. Em um cenário em que grande parte das avaliações de inteligência artificial é conduzida a partir de referências internacionais, o novo estudo ajuda a preencher uma lacuna importante ao medir o desempenho dos modelos a partir das necessidades reais da prática médica brasileira.
Por que o estudo é importante?
1. Avalia a IA em um contexto real da medicina brasileira
Grande parte dos benchmarks de inteligência artificial na saúde utiliza exames, bases de dados e diretrizes internacionais. Ao adotar o ENAMED 2026 como referência, o estudo avalia o desempenho dos modelos em um cenário alinhado à realidade da formação médica, dos protocolos clínicos e do contexto epidemiológico brasileiro.
2. Produz evidências científicas publicadas, padronizadas e comparáveis
Ao submeter dez modelos de IA às mesmas condições de teste, com perguntas, prompts e critérios padronizados, o benchmark permite comparar desempenho de forma transparente. Esse tipo de metodologia ajuda médicos, pesquisadores e instituições de saúde a compreender melhor as capacidades e limitações de cada sistema.
3. Mostra a importância da especialização em medicina
Os resultados indicam que modelos treinados para contextos específicos podem apresentar vantagens relevantes em tarefas médicas complexas. No estudo, o Charcot se destacou especialmente em questões relacionadas a diretrizes nacionais e protocolos clínicos brasileiros, reforçando o valor da especialização para aplicações em saúde.
4. Contribui para o desenvolvimento seguro da IA na medicina
Além da taxa de acertos, a pesquisa analisou aspectos como consistência das respostas, tempo de processamento e padrões compartilhados de erro entre os modelos. Esses achados ajudam a orientar o desenvolvimento de sistemas mais confiáveis e fornecem evidências importantes para a adoção responsável da inteligência artificial na medicina.
Além da taxa de acertos, os pesquisadores também analisaram o Tempo de Resposta Médio Normalizado (NMRT), uma métrica utilizada para comparar o tempo necessário para que cada modelo gerasse suas respostas. Os resultados apontaram uma associação positiva entre tempo de processamento e precisão, indicando que sistemas capazes de dedicar mais etapas ao raciocínio tendem a alcançar melhor desempenho em questões médicas complexas. O achado ajuda a compreender como diferentes arquiteturas de IA equilibram velocidade e qualidade na tomada de decisão.
O estudo também investigou o chamado Erro de Convergência (CE), fenômeno observado quando pelo menos três modelos selecionavam a mesma alternativa incorreta em todas as rodadas de execução. Mais do que identificar erros isolados, a abordagem permite detectar padrões sistemáticos compartilhados entre diferentes sistemas de IA. Segundo os autores, a métrica pode contribuir tanto para o aprimoramento dos modelos quanto para a validação de exames educacionais, ao ajudar a identificar questões potencialmente ambíguas ou suscetíveis a interpretações equivocadas.
O que é o Charcot, a IA médica da Voa Health?
Muito mais que uma ferramenta de transcrição capaz de ouvir, processar e documentar a conversa entre médico e paciente para melhorar a qualidade dos registros e reduzir a carga de digitação, a Voa integra diferentes etapas do cuidado em um fluxo contínuo e conectado ao contexto de cada paciente. O Charcot, que utiliza o contexto clínico para apoiar o raciocínio do médico e a busca por evidências, é peça-chave na plataforma. O assistente, que funciona como copiloto do médico antes, durante e depois da consulta, é uma ferramenta multipotente, que apoia os profissionais em várias frentes.
Por se tratar de uma tecnologia proprietária, detalhes sobre o funcionamento interno do Charcot não foram divulgados no estudo. Os pesquisadores avaliaram exclusivamente seus resultados, submetendo o sistema às mesmas condições aplicadas aos demais modelos participantes do benchmark. Dessa forma, a comparação concentrou-se no desempenho obtido na resolução das questões do ENAMED 2026, independentemente das diferenças de arquitetura ou implementação entre as ferramentas analisadas.
O que é o Charcot?
O Charcot é o agente clínico da Voa Health: uma IA especializada em medicina, criada para apoiar o raciocínio clínico, gerar insights com referências confiáveis e ajudar médicos a estruturar documentos, orientações e materiais a partir do contexto do atendimento. Diferente de uma IA genérica, quando usado dentro da Voa, ele considera o registro da consulta e informações relevantes do paciente. No benchmark publicado no JMIR Medical Education, o Charcot alcançou 96,97% de acertos no ENAMED 2026, obtendo o melhor desempenho entre os modelos avaliados.
O que é o ENAMED?
O Exame Nacional de Avaliação da Formação Médica (ENAMED) é uma avaliação que mede conhecimentos e competências adquiridos ao longo da graduação em medicina. A prova reúne questões de áreas como clínica médica, cirurgia, atenção primária, saúde pública, pediatria e ginecologia-obstetrícia. No estudo, o ENAMED 2026 foi utilizado como referência para comparar o desempenho de diferentes modelos de inteligência artificial em tarefas que exigem conhecimento médico.
Como o benchmark foi realizado?
Os pesquisadores aplicaram as questões do ENAMED 2026 a dez modelos de linguagem de larga escala (LLMs), incluindo o Charcot. Após a anulação de uma questão, 99 itens foram considerados válidos para análise. Cada modelo respondeu à prova completa em cinco rodadas independentes, sob as mesmas condições e utilizando prompts padronizados em português. O objetivo foi comparar a precisão, a consistência e o comportamento das diferentes inteligências artificiais diante dos mesmos desafios.
Por que o Charcot teve o melhor desempenho?
Segundo os resultados do estudo, o Charcot apresentou vantagem principalmente em questões relacionadas a diretrizes clínicas nacionais e aspectos específicos da prática médica brasileira. Desenvolvido para a língua portuguesa e treinado com foco no contexto da medicina brasileira, o sistema demonstrou maior aderência a protocolos e recomendações locais. Os achados sugerem que a especialização em medicina e contexto regional pode representar um diferencial importante em avaliações médicas de alta complexidade.
Quer ver na prática como o Charcot apoia a tomada de decisão e a busca por evidências na consulta? Conheça a Voa e tenha uma plataforma de IA especializada ao seu lado.
Charcot alcança 96,97% de acertos no ENAMED 2026 e supera modelos globais de IA em benchmark científico